
Eureka源码分析-(6)服务发现
总结
客户端
通过配置
eureka.client.fetch-registry=true开启拉取注册表,eureka.client.registry-fetch-interval-seconds=30拉取周期,这个拉取周期建议不要超过180秒,因为服务端的最近变更队列的元素超时周期就是180秒。超过了可能会导致有些变化获取不到,导致全部拉取。
-
实现方式
通过一个类似定时调度的线程池来实现按照指定周期来拉取的动作,增量获取会将服务端内最近180秒内变化的实例信息拉取过来,例如上线的、下线的、状态变更的等。拉到本地之后会和本地注册表合并,然后计算一致性
hash,利用这个hash和服务端的进行比对,如果不一致则需要重新全量拉取。
服务端
服务端通过一个最近变更队列来实现增量获取的功能,同时当服务上线、下线、状态变更、服务端主动剔除时会将这些变化的实例放到这个最近变更队列中并记录放入时间。然后启动一个线程池定时扫秒这个最近变更队列,当元素在队列中生存时间超过180秒后就会被剔除。这样每次客户端的增量获取请求都会读取这个最近变更队列。
一、服务发现之增量获取
如果开启了拉取注册列表
eureka.client.fetch-registry=true,那么在实例启动的时候,会执行一次全量获取,从注册中心拉取全量的注册表到本地缓存,之后按照默认配置eureka.client.registry-fetch-interval-seconds=3030秒/次更新一次本地缓存。
1、初始化定时调度
在
DiscoveryClient#initScheduledTasks的构造函数中可以看到,启动了一个定时调度,方式是和心跳续约一样的
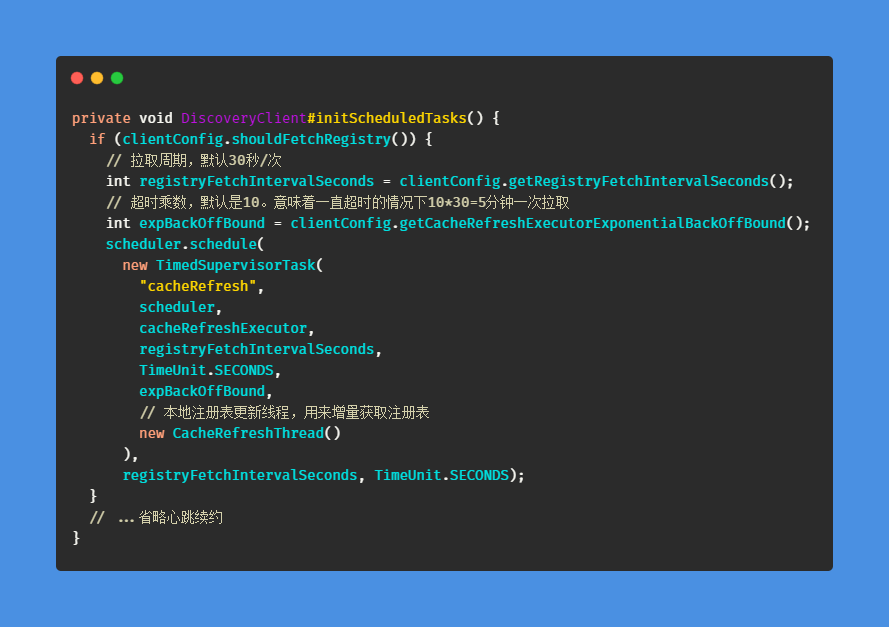
2、增量获取注册表
上一步的定时调度执行的任务是调用
DiscoveryClient#refreshRegistry()-->DiscoveryClient#fetchRegistry()而对于
fetchRegistry()方法的说明在上一篇文章中说过了,这里就不再赘述。我们直接看增量获取的
.png)
3、合并增量数据
对增量数据做合并,其中实例状态是从服务端传过来了;还记得之前的服务端的主动剔除、注销、注册操作吗?每个实例都会设置一下
ActionType,这里作用就体现到了。下面的代码片段删除了一些其他逻辑。
.png)
二、Eureka Server处理增量请求
1、处理请求接口
在
com.netflix.eureka.resources.ApplicationsResource#getContainerDifferential处理全量获取请求;和接口层面的处理和全量获取几乎一样,主要区别是请求类型
ResponseCacheImpl.ALL_APPS_DELTA
.png)
2、获取最近变更的实例信息
读取缓存的操作前面全量获取已经说过了,我们直接进入增量获取的部分
.png)
3、关于最近变更队列
可以看到增量获取的关键就是最近变更队列,通过之前的几章我们看到了,如果服务主动注销、被动剔除、注册操作都会向这个最近变更对列插入一个元素;
1)队列元素类型
数据结构很简单,一个是租约,一个是添加时间。这个
lastUpdateTime用来更新最近变更队列,剔除过期元素用的。
private static final class RecentlyChangedItem {
private long lastUpdateTime;
private Lease<InstanceInfo> leaseInfo;
public RecentlyChangedItem(Lease<InstanceInfo> lease) {
this.leaseInfo = lease;
lastUpdateTime = System.currentTimeMillis();
}
public long getLastUpdateTime() {
return this.lastUpdateTime;
}
public Lease<InstanceInfo> getLeaseInfo() {
return this.leaseInfo;
}
}
2)入队时机
-
服务注册时
可在
AbstractInstanceRegistry#register:264看到Lease<InstanceInfo> lease = new Lease<InstanceInfo>(registrant, leaseDuration); //... registrant.setActionType(ActionType.ADDED); recentlyChangedQueue.add(new RecentlyChangedItem(lease)); -
服务剔除时
可在
AbstractInstanceRegistry#internalCancel:325看到leaseToCancel = gMap.remove(id); //... InstanceInfo instanceInfo = leaseToCancel.getHolder(); //... instanceInfo.setActionType(ActionType.DELETED); recentlyChangedQueue.add(new RecentlyChangedItem(leaseToCancel)); -
服务注销时
服务注销和服务剔除最后调用同样的方法,入队逻辑相同。
-
实例状态更新时
可在
AbstractInstanceRegistry#statusUpdate:502处看到lease = gMap.get(id) InstanceInfo info = lease.getHolder(); info.setActionType(ActionType.MODIFIED); recentlyChangedQueue.add(new RecentlyChangedItem(lease));
3) 出队时机
通过一个定时调度,按照默认30秒/次扫秒最近变更队列。如果发现元素入队时间超过了3分钟就会被剔除。
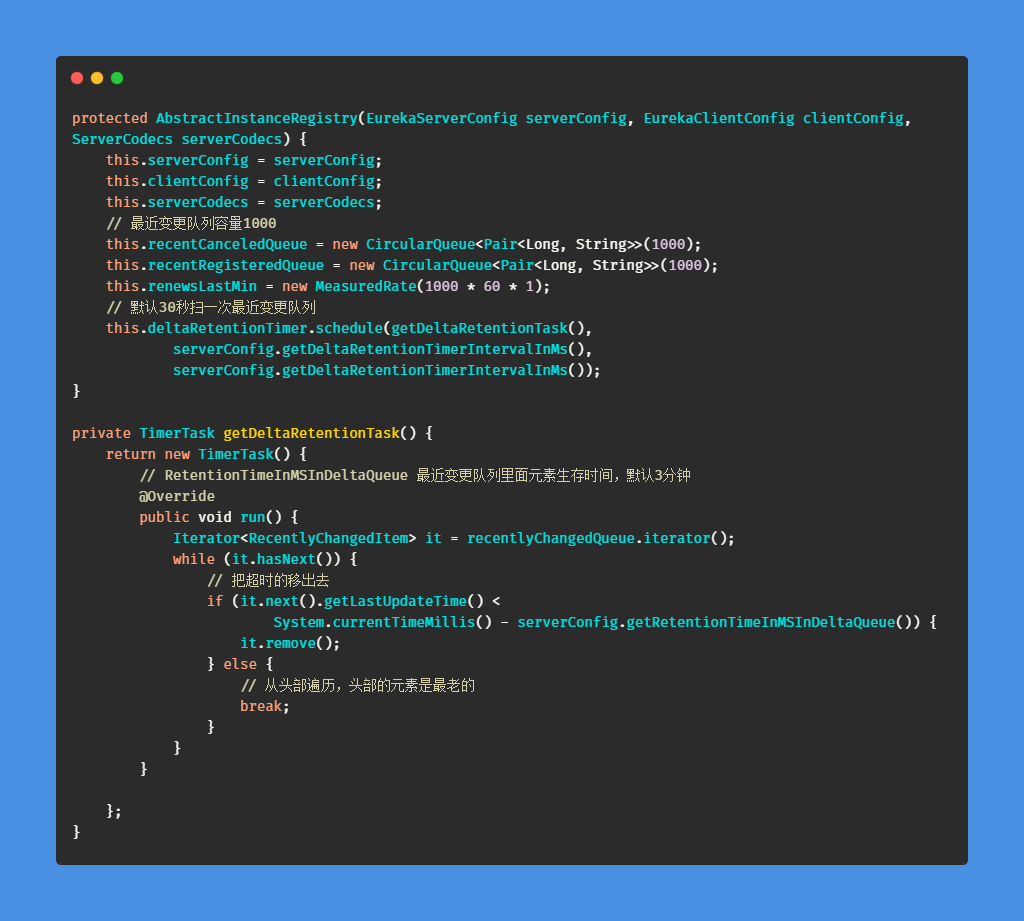
4、关于一致性hash
可以看到,在增量获取之后客户端会校验服务端传来的
hash是否和本地相等,如果不等则发起全量获取。但是这个
hash是不是有点过于简单了?只是拼接了几个服务在线几个服务下线...那么在增量获取期间,服务A下线,服务B上线。那么计算出来的hash会是一样的。当然默认情况下不会发生这种情况,因为最近变更队列元素生存周期是3分钟,而客户端会30秒拉一次。怎么着都会知道谁上线谁下线了。除非特殊情况把最近变更队列元素生存周期设置的比客户端拉取周期还短,才会发生这种情况。另外详见github上的讨论
-
计算方法
appsHashCode = status_+count_,如UP_3_DOWN_1